
尚书六号汉字表格识别系统是一款小巧好用的ocr识别软件,使用这款软件可以快速PDF、图片上面的文字转换成可以复制的文字或者可以编辑的文档,软件支持TIFF、BMP和JPG等常见图片格式,而且支持彩色、灰度图像文件直接进行OCR识别,有需要的快快下载吧。
主要特色
1、尚书六号支持TIFF、BMP和JPG格式等扫描。
2、OCR也就是文字识别技术,运用电脑或者扫描仪来识别图片或者数字图片文件里的文字内容,方便文字录入,提高工作效率。
3、支持彩色、灰度图像文件直接进行识别的OCR工具
4、使用只需要用本软件打开要识别的文字的图片,点击识别即可,识别率非常高,即便是有严重划痕和干扰的图片,也能达到惊人的98.5%!
使用教程
1. 扫描图像文件。
建议在桌面上直接使用SCANWIZARD 5软件,注意将软件切换到高级工作模式。原因是这样能便于用户检查扫描仪工作时的分辨率。
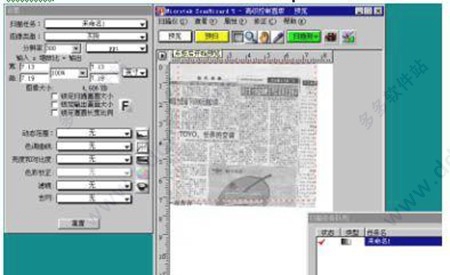
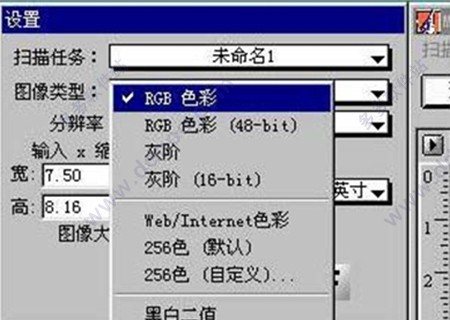
推荐的扫描分辨率设定在300DPI,色彩模式可以是“RGB彩色”或者“灰阶”
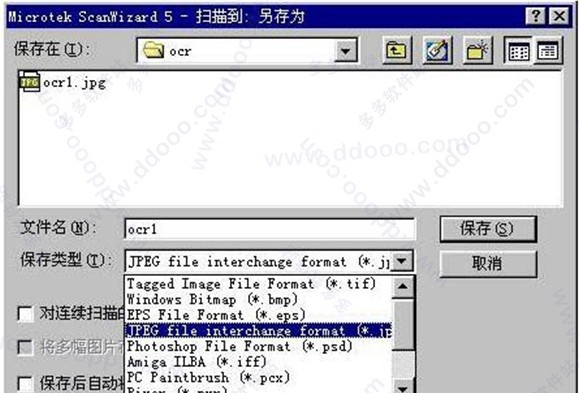
选择“扫描到”的文件格式是TIF或者JPG两者都可以。将扫描的文件存在用户确定的目录下面。
2. 打开尚书六号读取扫描好的图像文件。
3. 被识别图片的预处理。
这部分工作,主要包括:倾斜校正、设定正确的识别区域。
倾斜校正过程,如图所示,按下工具栏的最下面的一个工具。
按下“图像倾斜校正”工具后,会出现如下的对话窗口:
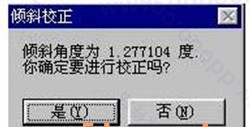
此时按下“是”按狃。系统就给予图片做水平的倾斜校正,做完后,结果如下:
注意,自动倾斜校正功能,只能对原稿做+-2.8度的倾角的校正,如果原稿的倾斜角度大于2.8度,系统会建议用户重新扫描稿件,以提高识别率。
如何正确设定识别区域,这是一个值得用户注意的地方:
如下的“海尔”一文,实际是分成两个栏目,进行阅读的,所以我们在设定识别区域的时候,注意需要将这个特点表现出来,需要设定两个识别区域,如图所示。
对于一些文字稿件,中间有图片的时候,我们建议采用绕开的方式,进行识别区域的设定,如下图:
4. 开始进行识别在开始”识别”的时候,注意识别的软件的设定值是否正确,默认值如下:

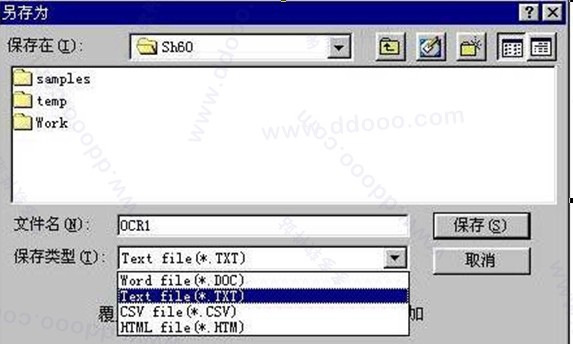
5. 识别校对完成后,存盘格式的选择文件保存的类型有四种,建议一般文本的识别,用户选择TXT格式。
如果是表格识别,识别结果请选择“CSV”格式,用EXCEL能够打开。
- 欧美顶级ppt免费模板网站 设计师必收藏的10个免费欧美ppt网站
- 申请中国签证如何拍照片 附中国签证申请相片规格要求
- Microsoft Office 2021官方正式破解版 简体中文下载
- 网页转轻应用如此简单一个“浏览器系统”App帮你一键完成高效浏览网站
- 阿里云oss上传工具ossutil详细教程
- Xcode13正式版40个新特性整理汇总
- 分享JSX行内样式与CSS互转工具
- 关于使用Xcode的奇技淫巧
- Office2022全家桶永久激活 终身授权
- word文档损坏怎么修复 docx文档修复破解教程
- 系统窗口美化工具Stardock WindowFX安装教程(附注册机)
- 电脑投屏软件Transcreen激活安装教程(附下载)
 疯狂动物园
疯狂动物园 模拟城市:我是市长
模拟城市:我是市长 军棋
军棋 少年名将
少年名将 冰雪王座
冰雪王座 烈焰封神
烈焰封神 彩虹物语
彩虹物语 我叫MT-标准版
我叫MT-标准版 塔防三国志Ⅱ
塔防三国志Ⅱ 玛法降魔传
玛法降魔传 花之舞
花之舞 明珠三国
明珠三国 赛尔号超级英雄
赛尔号超级英雄 票房大卖王
票房大卖王 忍者必须死3
忍者必须死3 全民接快递
全民接快递 小小突击队2
小小突击队2 弹弹岛2
弹弹岛2

